
Estos días están siendo muy duros para las acciones de las empresas tecnológicas y “parece” que una burbuja explotó. Para resumir lo que seguramente están viendo en todos lados: el modelo R1 de la China Deepseek “rompió” el paradigma de que para lograr modelos nuevos de IA hay que gastar miles de millones de dólares.
Claramente esos miles de millones de dólares tenían como destino las empresas tecnológicas y eso ahora puede estar en duda. Hasta ahí, porque si el 2025 en vez del año de los agentes es el año de la optimización de recursos con esos miles de millones se podrá hacer muchísimo más de lo esperado (que de por sí ya era mucho).
Además, abre la puerta a que países que (como Argentina) estaban lejos de poder entrenar grandes modelos ahora pueden aprovechar los recursos existentes y el recurso humano para entrar en la carrera o aunque no puedan estar entre los primero si tener dignos modelos con el contexto local…
Lo que es innegable (y que es para mí la clave) es que se pueden construir nuevas herramientas, ya sea para medios como para otro tipo de empresas, por una fracción del costo. ¿Qué idea loca tenías en mente que ya no es tan loca?
También en imágenes
Es inevitable que durante los próximos días también salgan nuevos modelos chinos y en este caso es uno de generación de imágenes Janus-Pro que está disponible para descargar y que promete resultados mejores que algunos modelos comerciales.
Además como su hermano R1, Deepseek lanza este modelo de imágenes con licencia comercial, así que cualquiera con recursos en servidores ya puede ofrecer R1 para razonamiento y Janus para generación de imágenes.

Algo que me parece rescatable de los nuevos modelos de imágenes y que ya al pobre DALL-E 3 lo dejaron muy viejito es lo bien que están entendiendo los nuevos proyectos cómo escribir y hacer que esos textos estén correctamente ajustados a texturas y luces, cosa que destacó en su momento a Flux.
Operadores
La semana pasada hablamos de OpenAI con su modelo que puede, por ejemplo, buscar un pasaje por nosotros, comparando no solo precios sino también comodidad, conveniencia y los detalles que queramos, no usando apis o códigos reservados sino navegando por internet como podríamos hacerlo de forma manual (y bastante mejor de lo esperado para una beta).
Bueno, la china Qwen de Alibaba acaba de lanzar Qwen2.5-VL un modelo que puede interactuar con computadoras y teléfonos, logrando así autonomía para asistirnos en tareas como, por ejemplo, comprar pasajes.
Además tiene una capacidad muy interesante, aunque pasó bastante por abajo del radar, que es la de analizar videos de hasta una hora, entender qué es lo que pasa e identificar objetos…
La carrera del sonido
Acá tenemos un favorito para canciones que es Suno y uno para audios voz ElevenLabs pero aunque su capacidad sea muy sorprendente no significa que estén solas en la carrera, nunca nos olvidemos de Adobe.
Los investigadores de la empresa presentaron MultiFoley hace unos días, un sistema de inteligencia artificial que genera automáticamente efectos de sonido sincronizados de posproducción para videos a través de indicaciones de texto, audio de referencia o clips de sonido existentes.
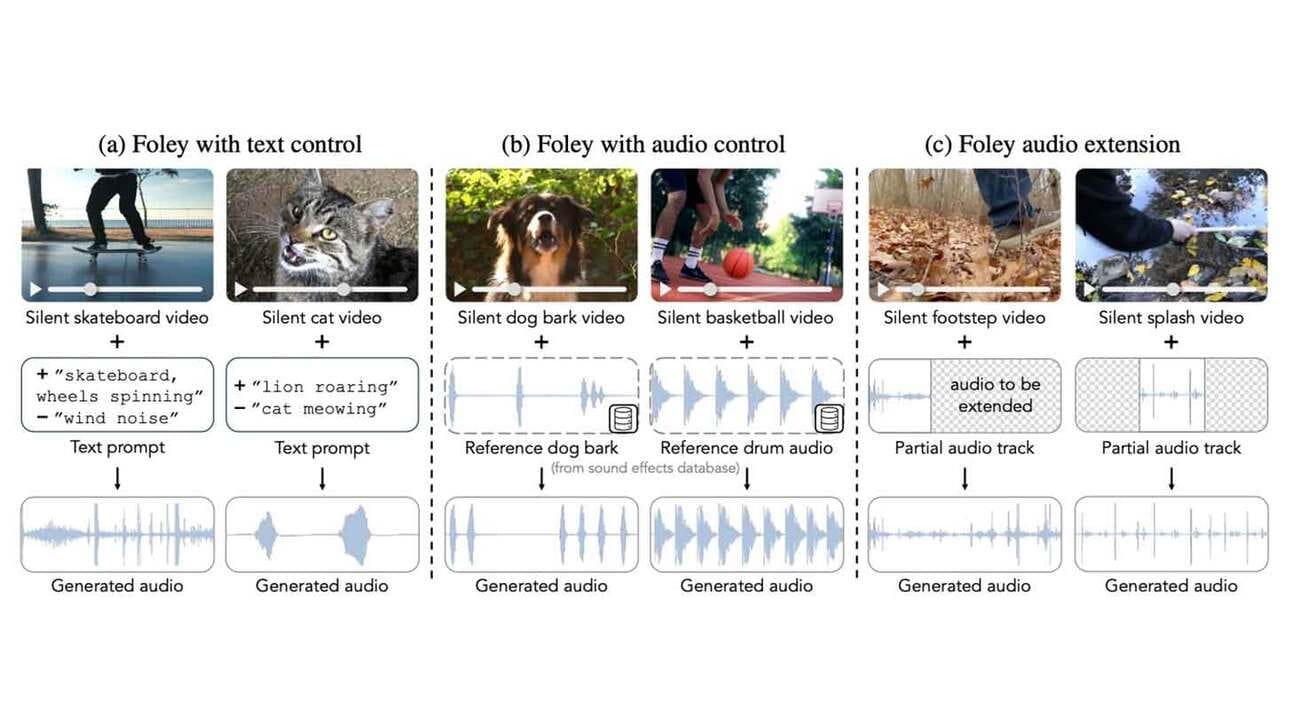
Fuente de la imagen: Adobe
Según los datos técnicos la calidad está en 48 kHz con una precisión de ajuste de 0,8 segundos. Se puede usar, además de para completar videos que no tengan el sonido adecuado, para cuestiones artísticas como cambiar el maullido de un gato por el rugido de un león sin que se pierda la sincronización (y en fracciones del tiempo empleado para hacerlo de forma manual).
Mejorar los prompts
Encontré ya varios posteos que hablan de mejoras en los prompts pensando en los razonadores. Comparto acá una indicación que me pareció interesante, pero que en lo particular aún no encontré diferencia de resultados.
La idea es ponerle delimitadores o etiquetas a las indicaciones, como si se tratara de un xml y dar las instrucciones así:

Usando <goal>, <context>, <format>, etc los resultados deberían ser mejores y más eficientes. Si hacen las pruebas con o1 o con R1 cuéntenme cómo les fue.
Qué estoy usando
En esta sección de cierre te cuento qué herramientas estoy usando en este momento porque, desde mi visión y uso, me da los mejores resultados (por respuesta o por costos).
Es algo súper íntimo y pueden no estar de acuerdo, pero creo que es una manera interesante de no solo decir “existe esto” si no “yo lo uso así” (o no).
Texto: o1 (plan plus), Redacta.Pro (de pago).
Video: Por ahora nada.
Audio: Elevenlabs (Free) y Adobe Audition (Pago).
Imágenes: Dall-E 3 (Pago) y Adobe Photoshop (Pago), BlinkShot (gratis, pero limitada) y ahora ImagenFX (3)
Programación: GPT 4o Canva o o1 plus
Buscador: Google y GPT Search (de pago).
Música: Suno.
Miscelánea: Endless.