
Diciembre es un mes de análisis, reflexión y comer mucho. Por eso, cuando planificaba los “Cada tanto” dije: “Bueno, diciembre tranquilo, piano piano, un envío en el mes y nos leemos en enero”. La cuestión es que todo se volvió una auténtica locura, muy difícil de procesar y probar como para poder contar todo lo que pasa.
Así que durante los próximos envíos vamos a “repasar” un poco las noticias, pero voy a tratar de rescatar, junto a ustedes, las herramientas y anuncios para sacarle provecho y no solo enumerar de forma superficial la actualidad.
Dicho esto, tenemos 2 grandes noticias: OpenAI hizo un calendario de adviento con 12 anuncios en 12 días hábiles y Google lanzó nuevas herramientas y modelos que la dejan bastante cómoda en esa carrera que venimos describiendo por ver cuál es la primera empresa en lograr una Inteligencia Artificial de verdad.
Así que hoy nos vamos a enfocar en algunas de las cosas que presentaron estas dos organizaciones y posiblemente en un par de días entramos en más detalles de otros anuncios.
Más tiempo = mejores resultados
OpenAi presentó o1 final y el modo pro, sus dos versiones finales del modelo de razonamiento o1. Para los que se sumen ahora, un modelo de razonamiento tiene un entrenamiento como los demás modelos del lenguaje (LLM) pero en vez de “escupir” la respuesta, la “mastica un poco”, se “hace preguntas”, divide el pedido en varias partes y se toma “un rato para pensar”.
La explicación puede ser básica, pero en esencia es lo que hace. ¿Es perfecto? No, pero de verdad se nota la diferencia en la profundidad y enfoque de los resultados.
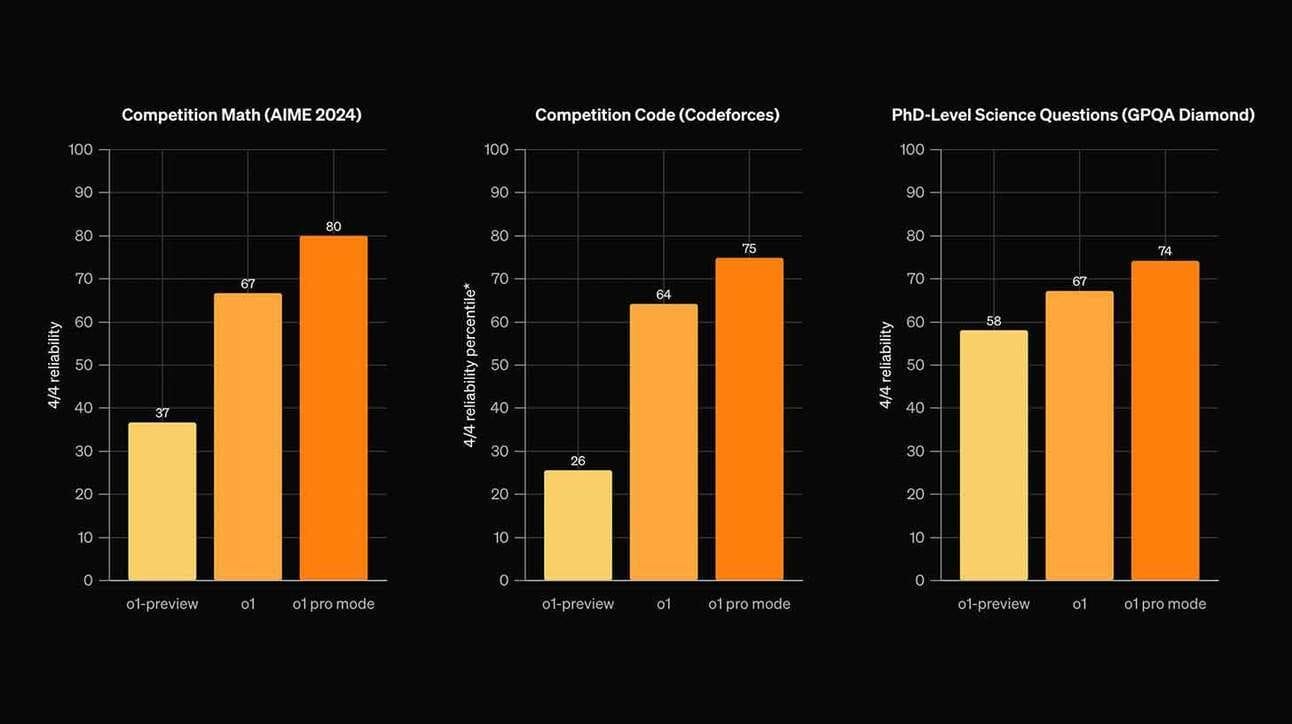
Fuente de la imagen: OpenAI
El modelo o1 final también puede procesar imágenes y según sus creadores es más eficiente a la hora de responder (elije cuánto tiempo dedicar según la complejidad del pedido), mejorando la experiencia y reduciendo 34 % los errores en tareas complejas (también según sus creadores).
El otro “regalito” fue la salida de la suscripción Pro por 200 dólares al mes (que se suma a la opción de la plus de 20 dólares). Esta es la manera de acceder al modo o1 Pro, que como se ve en el gráfico es un poco mejor. Además te da acceso ilimitado a las consultas, a Sora en el modo relajado (ya veremos qué es esto), y algunas cosas más.
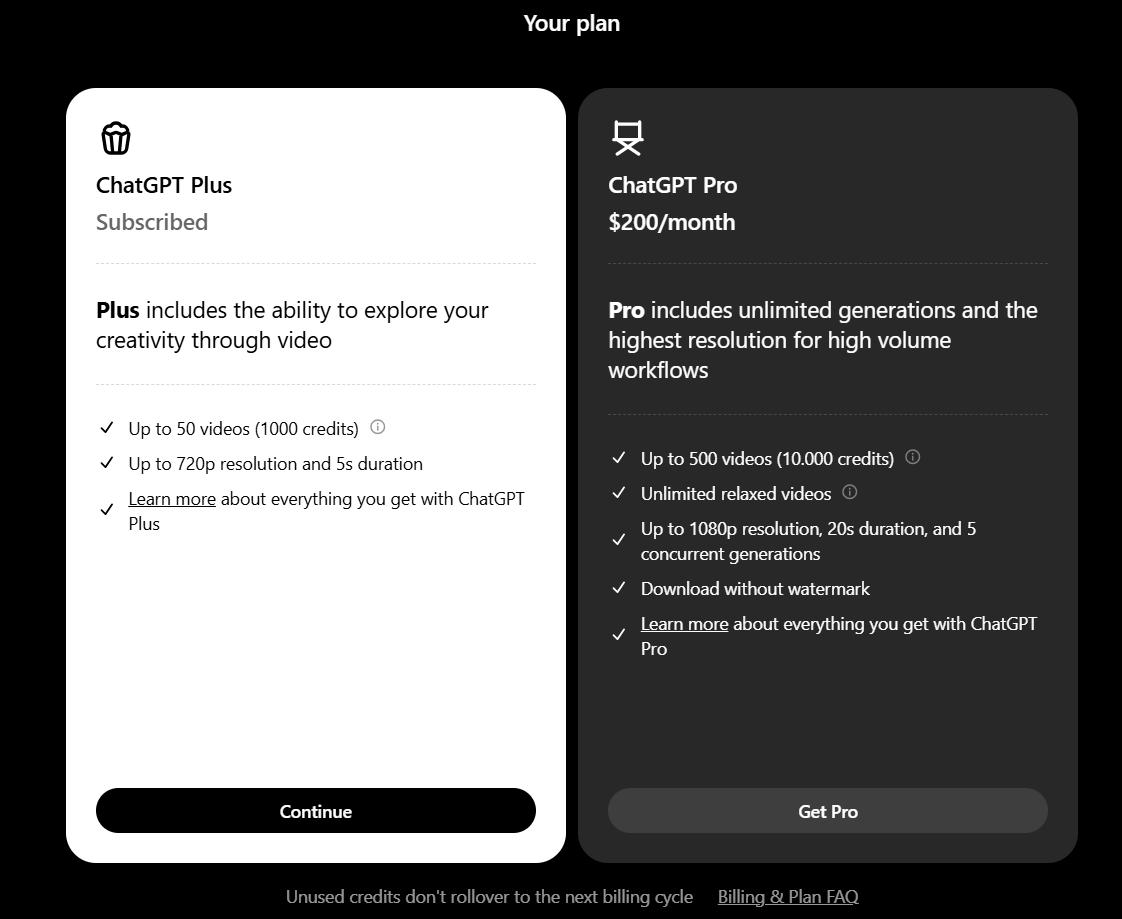
Personalmente ya lo estoy usando (el plus) para codificación y gestión de proyectos y la verdad que supera ampliamente los resultados conseguidos con 4o o en programación a Claude Sonnet 3.5.
Salió Sora! Pero…
Anunciado en Febrero, el calendario traía a Sora, el generador de video de OpenAI en el que uno le pone un texto y genera una video gastando créditos según la cuenta que tengas.

Es un modelo, como los otros, en el que se puede elegir la configuración de aspecto y la duración (según tu plan podés llegar a 20 segundos) y mediante prompts ir probando hasta lograr un resultado que sea de tu agrado.
Dos problemas: en Europa aún no está disponible y amenazaron banear cuentas que usen VPNs así que lo probé una vez y no me arriesgue más. El segundo problema, y es mi conclusión tras ver muchas reseñas, es que para llegar a un resultado que de verdad sea sorprendente hay que probar muchas veces lo que hace que los límites del plan se queden un poco cortos, más teniendo en cuenta competidores de muy buen nivel a mitad de precio.
Pero también como hemos visto en otros casos, los modelos mejoran, todo cambia… así que ni bien pueda les voy a subir un corto propio (ya en 2025).
Las apuestas de Google
La empresa del buscador lanzó Gemini 2.0, su nueva familia de modelos con mejores resultados y optimización de costos. Esta parte, la de los costos, no es algo menor porque para desarrollar aplicaciones (por ejemplo Redacta.Pro la herramienta de Tres Barbas) se usan las APIs de empresas de IA y mejores costos y mejor velocidad es algo muy deseable.
Y en ese universo debuta Gemini 2.0 Flash, que es más rápido y supera a 1.5 Pro en varios puntos de referencia. Algo que también se está haciendo una suerte de estándar: el modelo baratito y rápido de la nueva generación está al nivel del pro de la generación anterior.
Gemini 2.0 además genera imágenes y audio multilenguaje de forma directa, procesa código, imágenes y también video, con una versión para probarlo de forma gratuita. Google también mostró varios proyectos en los que están trabajando, pero los analizaremos cuando estén públicos.

Fuente de la imagen: Google
Lo que ya está en lista de espera es Veo 2 (el Sora de Google), un modelo de generación de video y el de imágenes ocurrentemente denominado Imagen 3.
Según las características, Veo 2 puede generar clips de 8 segundos con una resolución de 4K (720p en el lanzamiento), muestra mejoras masivas en la simulación física y alucinaciones reducidas, lo que genera movimientos y detalles más realistas.
Por parte de Imagen 3, mejoraron los colores y el realismo, mejor interpretación y calidad visual, a nivel o incluso mejor según ellos que Midjourney, Flux e Ideogram.
Acá les recomiendo VPN (guiño guiño) si no los deja acceder y escribir las peticiones en inglés.
Parece que el modelo que quedó más relegado es Dall-E 3, el de GPT, pero el calendario todavía tiene algunos días…
Qué estoy usando
En esta sección de cierre te cuento qué herramientas estoy usando en este momento porque, desde mi visión y uso, me da los mejores resultados (por respuesta o por costos).
Es algo súper íntimo y pueden no estar de acuerdo, pero creo que es una manera interesante de no solo decir “existe esto” si no “yo lo uso así” (o no).
Texto: o1 (plan plus), Redacta.Pro (de pago).
Video: Por ahora nada.
Audio: Elevenlabs (Free) y Adobe Audition (Pago).
Imágenes: Dall-E 3 (Pago) y Adobe Photoshop (Pago), BlinkShot (gratis, pero limitada) y ahora ImagenFX (3)
Programación: GPT 4o Canva o o1 plus
Buscador: Google y GPT Search (de pago).
Música: Suno.
Miscelánea: Endless.